Dalam machine learning, salah satu tantangan utama adalah menemukan keseimbangan antara model yang terlalu sederhana (underfitting) dan model yang terlalu kompleks (overfitting). Kedua masalah ini dapat membuat model gagal memberikan prediksi yang akurat pada data baru, meskipun performa di training data terlihat baik.
Artikel ini akan membahas cara mendeteksi, mencegah, dan mengatasi overfitting serta underfitting agar model yang kamu bangun dapat bekerja optimal di dunia nyata.
Apa itu Overfitting?
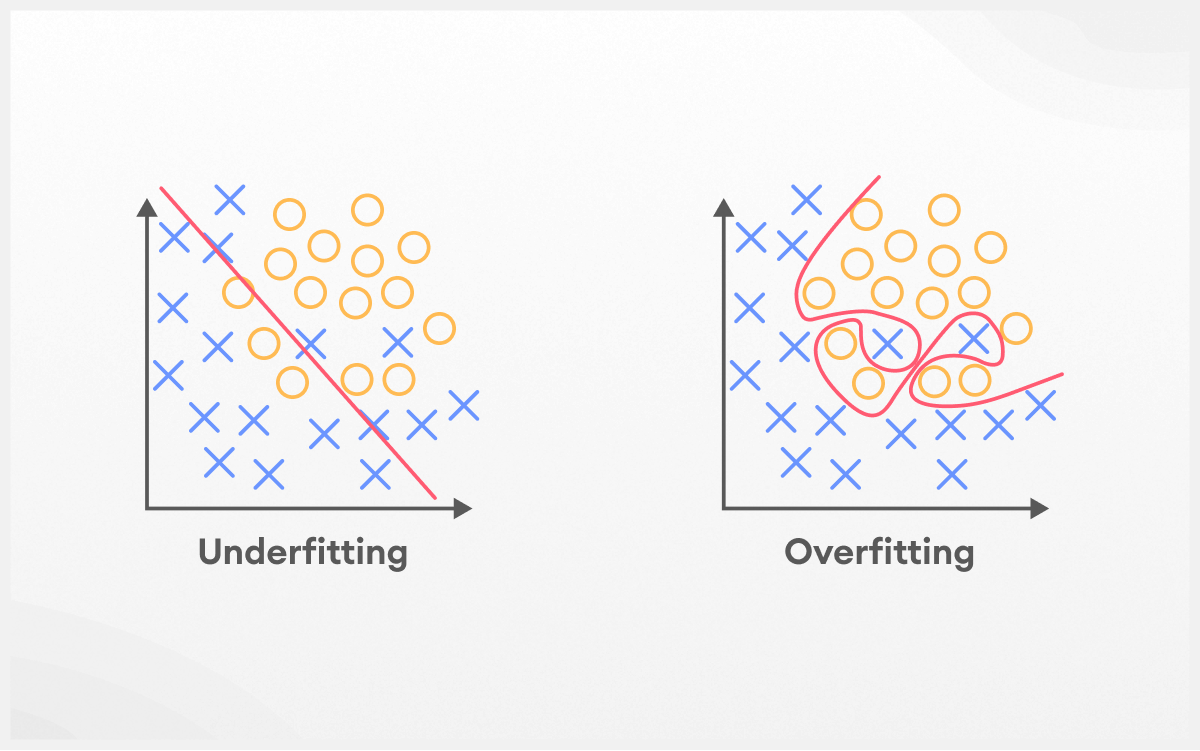
Overfitting terjadi ketika model terlalu "pintar" dan menghafal detail spesifik dari training data, termasuk noise dan anomali yang sebenarnya tidak penting. Model yang overfitting akan menunjukkan performa sangat baik pada training data, tetapi buruk pada validation atau test data.
Ciri-ciri Overfitting
Model mengalami overfitting jika training accuracy tinggi (misalnya 95%) tapi validation accuracy rendah (misalnya 70%). Gap yang besar antara training dan validation performance adalah red flag utama overfitting. Learning curves menunjukkan training error yang terus menurun sementara validation error mulai naik atau stagnan.
Penyebab Overfitting
Overfitting sering terjadi pada model yang terlalu kompleks dibanding jumlah data yang tersedia. Deep neural networks dengan banyak parameter, decision trees yang sangat dalam, atau polynomial regression dengan degree tinggi rentan mengalami overfitting. Training terlalu lama juga bisa menyebabkan model mulai menghafal noise dalam data.
Apa itu Underfitting?
Underfitting adalah kebalikan dari overfitting, dimana model terlalu sederhana untuk menangkap pola yang ada dalam data. Model underfitting akan menunjukkan performa buruk baik pada training maupun validation data.
Ciri-ciri Underfitting
Training dan validation accuracy sama-sama rendah, misalnya keduanya sekitar 60%. Model tidak bisa belajar pola dasar dari data, sehingga error rate tinggi di semua dataset. Learning curves menunjukkan plateau di level performa yang rendah.
Penyebab Underfitting
Underfitting terjadi ketika model terlalu simple untuk kompleksitas masalah. Menggunakan linear regression untuk data non-linear, algoritma dengan parameter terbatas, atau regularization yang terlalu kuat dapat menyebabkan underfitting. Feature yang tidak cukup informatif juga berkontribusi pada masalah ini.
Cara Mendeteksi Overfitting dan Underfitting
Learning Curves
Learning curves adalah tool utama untuk diagnosis. Plot training dan validation performance terhadap jumlah data atau epoch training. Overfitting terlihat dari gap yang melebar antara training dan validation curves. Underfitting terlihat dari kedua curves yang plateau di level rendah.
Cross-Validation
Gunakan k-fold cross-validation untuk evaluasi yang robust. Variance tinggi antar fold menunjukkan overfitting, sementara mean score rendah di semua fold mengindikasikan underfitting.
Validation Curves
Plot performance terhadap hyperparameter seperti model complexity. Overfitting terlihat ketika validation performance turun meski training performance naik seiring bertambahnya complexity.
Mengatasi Overfitting
Regularization
Tambahkan penalty term untuk mengurangi kompleksitas model. L1 regularization (Lasso) dapat melakukan feature selection otomatis, sementara L2 regularization (Ridge) mengecilkan coefficient tanpa menghilangkannya. Elastic Net menggabungkan keduanya.
Early Stopping
Untuk algoritma iteratif, monitor validation performance dan stop training ketika mulai memburuk. Ini mencegah model menghafal noise di tahap akhir training.
Data Augmentation
Tingkatkan variasi data training dengan transformasi yang mempertahankan label. Untuk image data, gunakan rotasi, translation, scaling. Untuk text, gunakan synonym replacement atau paraphrasing.
Ensemble Methods
Gabungkan multiple models untuk mengurangi variance. Random Forest, Bagging, atau Gradient Boosting dapat mengurangi overfitting melalui averaging predictions.
Feature Selection
Buang features yang tidak relevan atau redundant. Gunakan techniques seperti Recursive Feature Elimination atau univariate feature selection.
Mengatasi Underfitting
Increase Model Complexity
Gunakan algoritma yang lebih sophisticated atau tambahkan parameters. Ganti linear model dengan tree-based methods, atau tambahkan hidden layers pada neural networks.
Feature Engineering
Buat features baru yang lebih informatif. Tambahkan polynomial features, interaction terms, atau transformasi domain-specific yang menangkap pola penting dalam data.
Reduce Regularization
Kurangi strength regularization atau hilangkan sama sekali jika over-regularization menjadi penyebab underfitting. Monitor validation performance untuk menghindari swing ke overfitting.
More Training Data
Kumpulkan data tambahan yang lebih diverse atau representative dari problem domain. Data yang berkualitas dan cukup banyak membantu model belajar pola yang genuine.
Tools untuk Diagnosis
Python Libraries
Gunakan scikit-learn untuk metrics dan diagnostic tools. Matplotlib dan Seaborn untuk visualisasi learning curves. Yellowbrick menyediakan high-level visualizations untuk model diagnosis.
Model Interpretation
SHAP dan LIME membantu understand feature importance dan detect spurious correlations yang menandakan overfitting. Permutation importance juga berguna untuk validasi feature relevance.
Experiment Tracking
MLflow atau Weights & Biases untuk systematic hyperparameter tuning dan model comparison. TensorBoard untuk monitoring neural network training progress.
Kesimpulan
Menemukan balance antara overfitting dan underfitting adalah kunci sukses dalam machine learning. Gunakan diagnostic tools seperti learning curves dan cross-validation untuk early detection. Implementasikan regularization dan early stopping untuk prevent overfitting, sementara increase model complexity dan improve features untuk address underfitting.
Remember bahwa optimal balance tergantung pada specific problem dan available data. Practice regular dengan berbagai techniques dan build intuition melalui experimentation. Goal utama adalah model yang generalize well ke unseen data, bukan yang perfect pada training data.
Dengan understanding yang solid tentang bias-variance tradeoff dan practical tools untuk diagnosis dan mitigation, kamu dapat consistently build models yang deliver reliable performance di real-world applications. Semoga bermanfaat…